Optimizing Storage: String Compression
Smush it into a string
I built a note-taking app recently, and decided on using Lexical for the text editor. It has great built-in features and is extremely customizable, but one downside is the output file for the note state.
It generates a .lexical file that is essentially a JSON file, and it can get pretty large. There is a minimum size of the file. For example, saving just a few lines of text results in a multi-kilobyte file.
Since I'm storing these notes in Postgres, and saving space is a priority, I explored ways to reduce the file size.
In general, I would store large JSON objects in some blob or object storage, but in this case the compressed and minified output is a tiny string.
Minification
The first thing I started to do was build a minifier for the lexical file. Luckily, before I got too far I found a really good implementation of a minifier for lexical files.
Manually creating a minifier and array packing is interesting and broad enough that it deserves a separate article, but I suggest taking a look at the code.
Compression
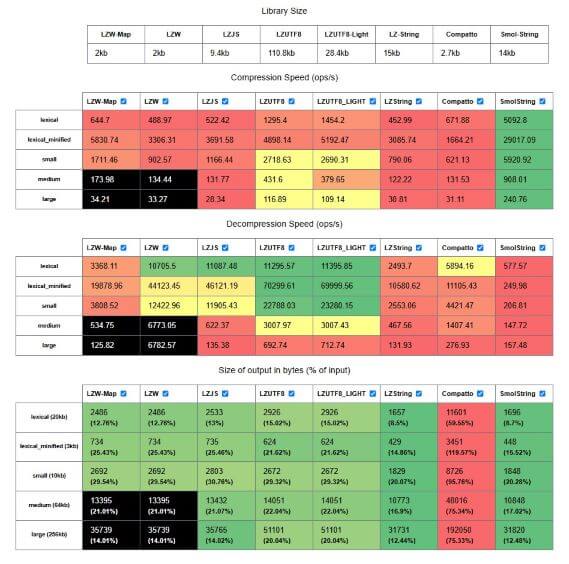
Looking at the Lexical data structure, even the minified output, I noticed a lot of repeated properties. With only a handful of properties and values being used repeatedly, this structure was an ideal candidate for compression. But not all compression algorithms are the same. I decided to test a few to see which would perform best for my needs.
Evaluating Algorithms
Huffman Coding
Huffman coding is a frequency-sorted binary tree algorithm. It assigns shorter codes to more frequent characters. It's a great general-purpose compression method and is used in conventional compressions formats like gzip.
{ f:0, c:100, d:101, a:1100, ... }
Lempel-Ziv-Welch (LZW)
LZW builds a dictionary of patterns from the input data. It has an interesting history of legal issues. Depending on the implementation and style of encoding, the output can be:
A map of encoded character frequency:
{ "0": 123, "1": 34, "2": 99, "3": 34, ... }
A binary array:
[ 123, 34, 99, 34, ...]
An encoded string
㞂張䔲...
What Matters Most for My Use Case
When choosing a compression approach, there are four factors to consider - compression speed, decompression speed, compressed size, and output format.
Decompression speed
In my app's case, decompression happens only once, when the frontend retrieves and processes the saved note. Whether it takes 1ms or 50ms is irrelevant. Even the slowest algorithm can decompress a single encoded string fast enough that it's imperceptible, and the GET request will account for more of the loading time.
Compression speed
Similarly, compression happens asynchronously in the app. When a user is writing a note, the text input is debounced and an async POST request is made. This whole process is opaque to the user and doesn't effect the frontend, so speed is also not a concern here.
Compressed Size
The primary metric I care about is compressed size. Smaller sizes mean reduced storage costs and faster network transfers.
Actual Output
Some of the libraries I tested output encoded characters that were incomptible with sending through HTTP or saving within a postgres text or jsonb column.
Luckily, it's straightforward enough to get an encoded string from an LZW implementation, which also happened to be one of the smaller, faster algorithms.
Final Approach
I eventually decided to minify the file first, then compress it with a customized LZWLite implementation. In my initial testing, I was able to reduce a 20KB Lexical file to a 1.2KB string that could reliably be decompressed.
If you're working with Lexical files or other JSON-based formats, I'd recommend checking out the Lexical Minifier. If you're curious about my tests or want to add more compression algorithms, feel free to open a PR on my repo!